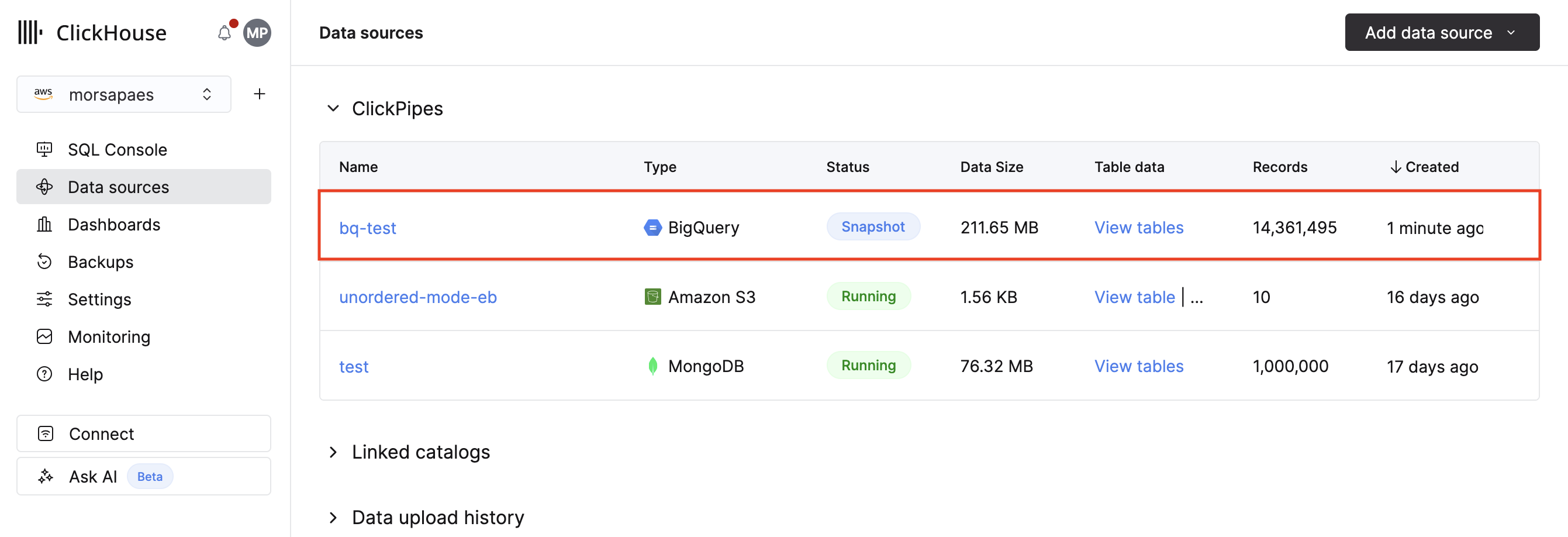
Создание первого BigQuery ClickPipe
Вы можете записаться в список ожидания Private Preview здесь.
ClickPipe для BigQuery предоставляет полностью управляемый и отказоустойчивый способ приёма данных из BigQuery в ClickHouse Cloud. В рамках Private Preview он поддерживает метод репликации initial load, позволяющий массово загружать наборы данных BigQuery для исследования и прототипирования. Поддержка CDC будет добавлена в будущем — до тех пор мы рекомендуем использовать Google Cloud Storage ClickPipe для непрерывной синхронизации экспортируемых данных BigQuery с ClickHouse Cloud после завершения первоначальной загрузки.
ClickPipes для BigQuery могут развёртываться и управляться вручную через интерфейс ClickPipes, а также программно с использованием OpenAPI и Terraform.
Предварительные требования
-
У вас должны быть привилегии для управления service accounts и IAM roles в вашем GCP-проекте, либо вам нужно обратиться за помощью к администратору. Мы рекомендуем создать отдельный service account с минимально необходимым набором permissions в соответствии с официальной документацией.
-
Для первичной загрузки требуется Google Cloud Storage (GCS) bucket, предоставленный пользователем, для промежуточного хранения (staging). Мы рекомендуем создать отдельный bucket для вашего ClickPipe согласно официальной документации. В дальнейшем промежуточный bucket будет предоставляться и управляться ClickPipes.
Выбор источника данных
1. В ClickHouse Cloud выберите Data sources в основном навигационном меню и нажмите Create ClickPipe.
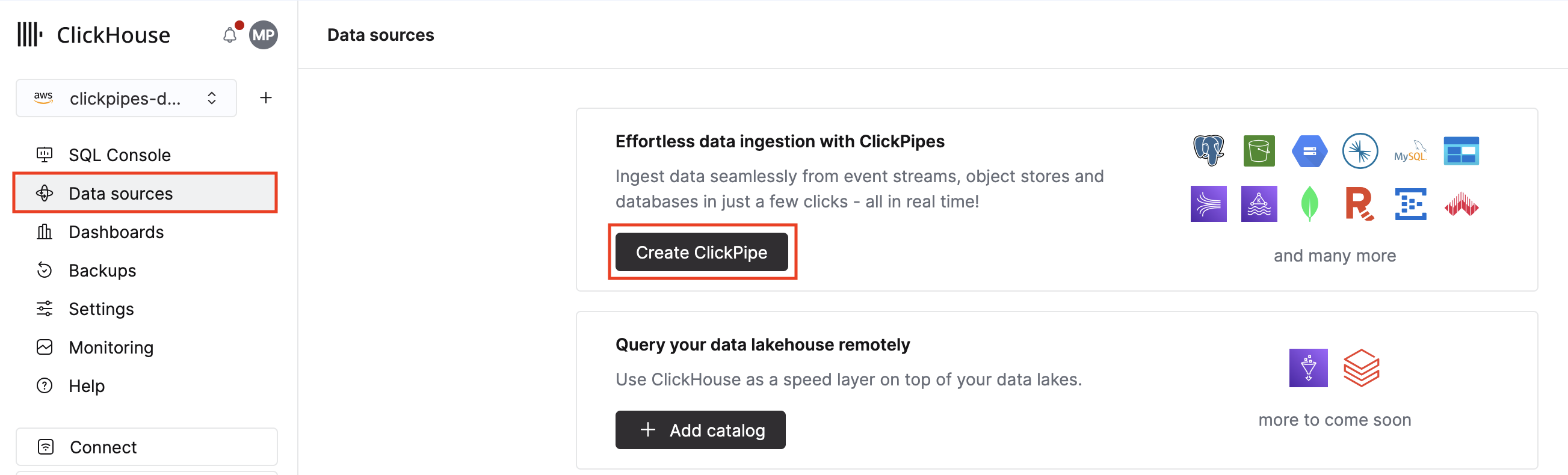
2. Нажмите на плитку BigQuery.
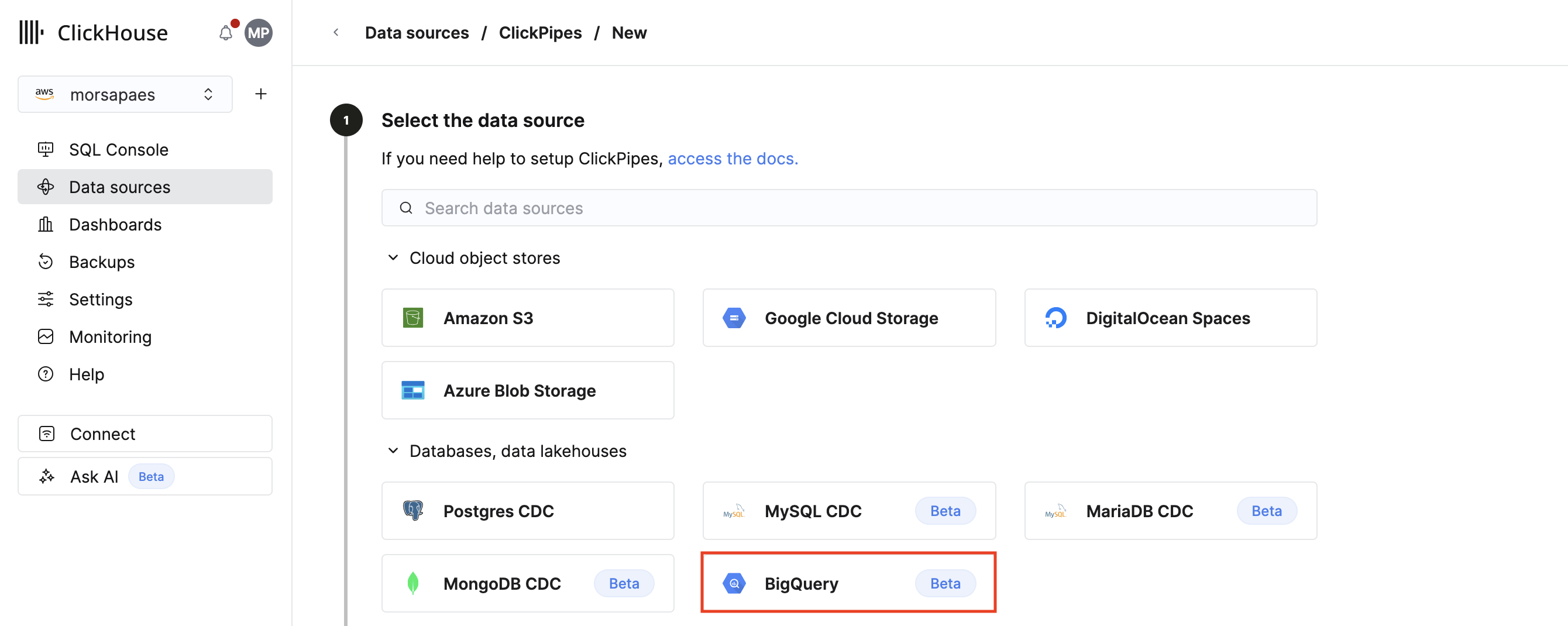
Настройка подключения ClickPipe
Чтобы настроить новый ClickPipe, необходимо указать параметры подключения и аутентификации к вашему хранилищу данных BigQuery, а также staging GCS bucket.
1. Загрузите .json-ключ для service account, который вы создали для ClickPipes. Убедитесь, что у service account есть минимально необходимый набор permissions.
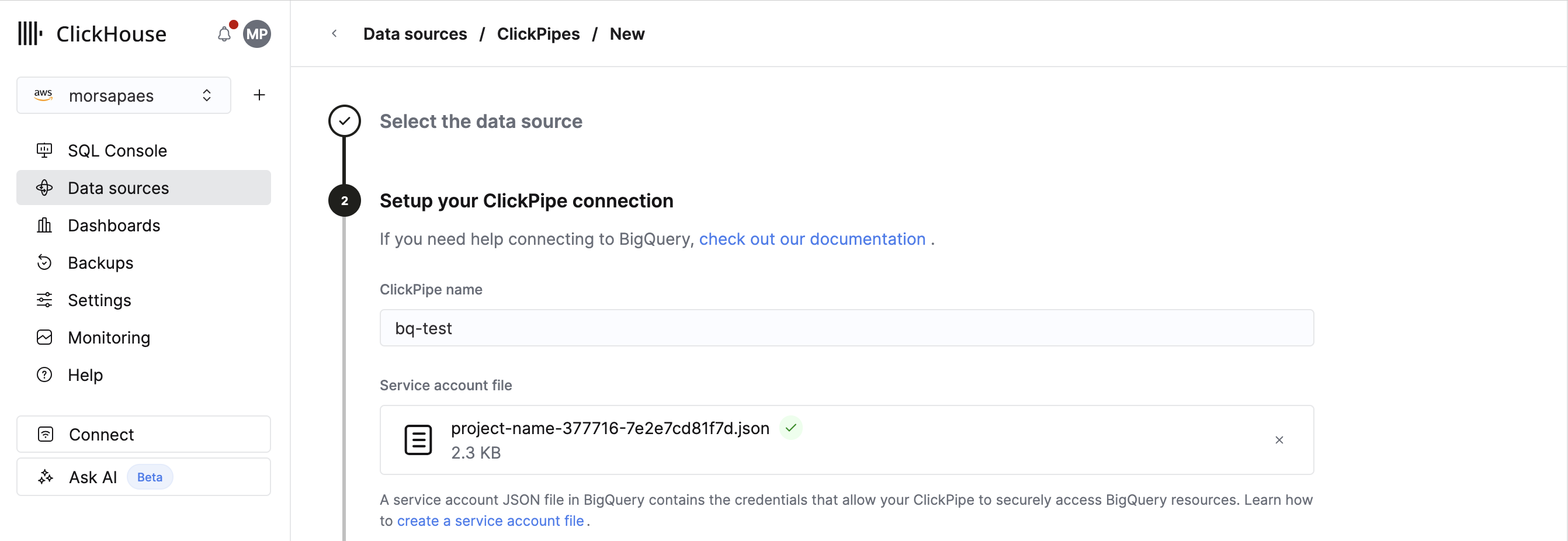
2. Выберите Replication method. В рамках Private Preview поддерживается только вариант Initial load only.
3. Укажите путь к GCS bucket для промежуточного хранения данных во время первичной загрузки.
4. Нажмите Next для проверки.
Конфигурация ClickPipe
В зависимости от размера вашего набора данных BigQuery или общего объёма таблиц, которые вы хотите синхронизировать, может потребоваться скорректировать настройки ингестии по умолчанию для ClickPipe.
Настройка таблиц
1. Выберите базу данных ClickHouse, в которую должны реплицироваться таблицы BigQuery. Вы можете выбрать существующую базу данных или создать новую.
2. Выберите таблицы и, при необходимости, столбцы, которые вы хотите реплицировать. Будут перечислены только те наборы данных, к которым имеет доступ указанный service account.
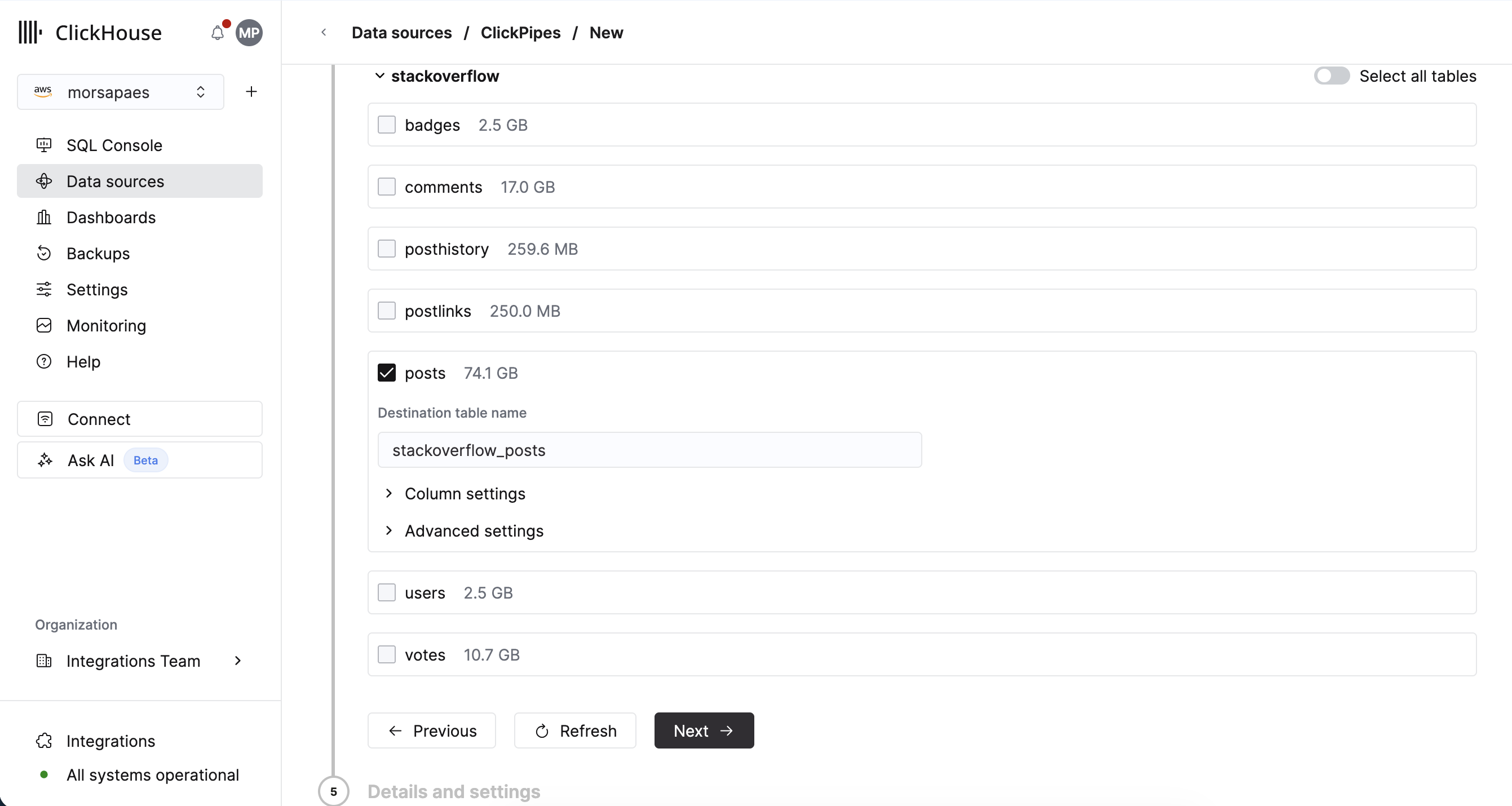
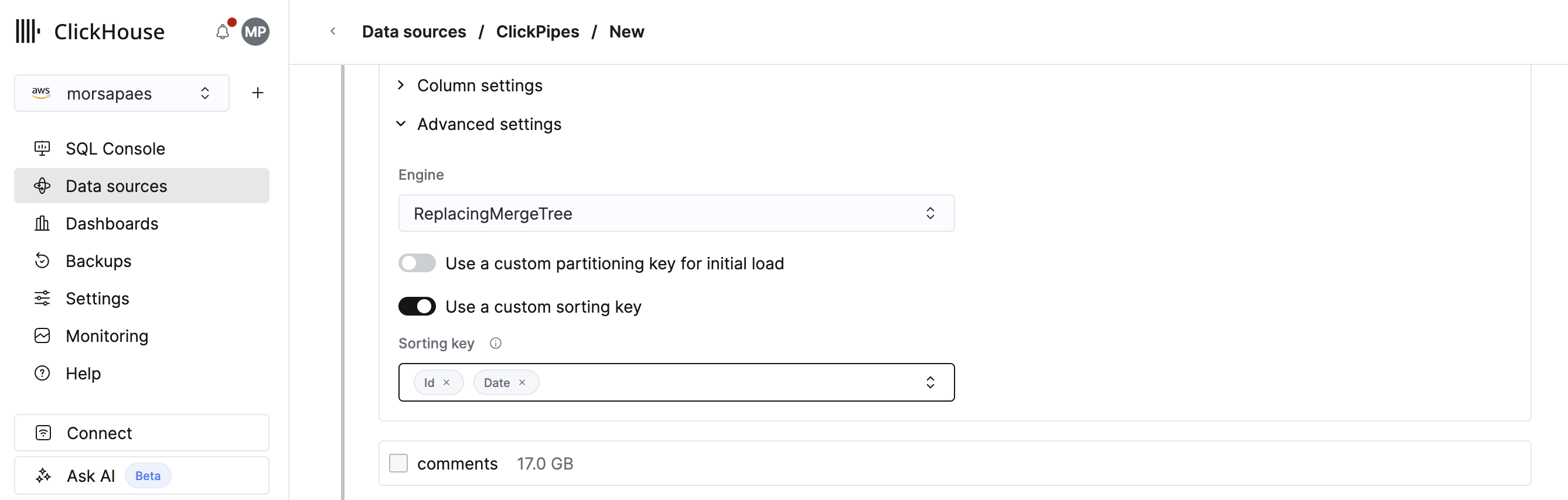
3. Для каждой выбранной таблицы обязательно задайте пользовательский ключ сортировки в разделе Advanced settings > Use a custom sorting key. В дальнейшем ключ сортировки будет автоматически определяться на основе существующих ключей кластеризации или партиционирования во внешней базе данных.
Вы обязаны задать sorting key для реплицируемых таблиц, чтобы оптимизировать производительность запросов в ClickHouse. В противном случае ключ сортировки будет установлен как tuple(), что означает отсутствие первичного индекса, и ClickHouse будет выполнять полное сканирование таблицы для всех запросов к этой таблице.
Настройка прав доступа
Наконец, вы можете настроить права доступа для внутреннего пользователя ClickPipes.
Permissions: ClickPipes создаст отдельного пользователя для записи данных в целевую таблицу. Вы можете выбрать роль для этого внутреннего пользователя, используя настраиваемую роль или одну из предопределённых ролей:
Full access: полный доступ к кластеру. Требуется, если вы используете materialized views или словарь с целевой таблицей.Only destination: права на вставку только в целевую таблицу.
Завершение настройки
Нажмите Create ClickPipe, чтобы завершить настройку. Вы будете перенаправлены на страницу обзора, где сможете просматривать прогресс первичной загрузки и переходить к деталям ваших BigQuery ClickPipes.